This post is the fourth and last in the series ECC: a gentle introduction.
In the last post we have seen two algorithms, ECDH and ECDSA, and we have seen how the discrete logarithm problem for elliptic curves plays an important role for their security. But, if you remember, we said that we have no mathematical proofs for the complexity of the discrete logarithm problem: we believe it to be “hard”, but we can’t be sure. In the first part of this post, we’ll try to get an idea of how “hard” it is in practice with today’s techniques.
Then, in the second part, we will try to answer the question: why do we need elliptic curve cryptography if RSA (and the other cryptosystems based on modular arithmetic) work well?
Breaking the discrete logarithm problem
We will now see the two most efficient algorithms for computing discrete logarithms on elliptic curve: the baby-step, giant-step algorithm, and Pollard’s rho method.
Before starting, as a reminder, here is what the discrete logarithm problem is about: given two points $P$ and $Q$ find out the integer $x$ that satisfies the equation $Q = xP$. The points belong to a subgroup of an elliptic curve, which has a base point $G$ and which order is $n$.
Baby-step, giant-step
Before entering the details of the algorithm, a quick consideration: we can always write any integer $x$ as $x = am + b$, where $a$, $m$ and $b$ are three arbitrary integers. For example, we can write $10 = 2 \cdot 3 + 4$.
With this in mind, we can rewrite the equation for the discrete logarithm problem as follows: $$\begin{align*} Q & = xP \\ Q & = (am + b) P \\ Q & = am P + b P \\ Q - am P & = b P \end{align*}$$
The baby-step giant-step is a “meet in the middle” algorithm. Contrary to the brute-force attack (which forces us to calculate all the points $xP$ for every $x$ until we find $Q$), we will calculate “few” values for $bP$ and “few” values for $Q - amP$ until we find a correspondence. The algorithm works as follows:
- Calculate $m = \left\lceil{\sqrt{n}}\right\rceil$
- For every $b$ in ${0, \dots, m}$, calculate $bP$ and store the results in a hash table.
- For every $a$ in ${0, \dots, m}$:
- calculate $amP$;
- calculate $Q - amP$;
- check the hash table and look if there exist a point $bP$ such that $Q - amP = bP$;
- if such point exists, then we have found $x = am + b$.
As you can see, initially we calculate the points $bP$ with little (i.e. “baby”) increments for the coefficient $b$ ($1P$, $2P$, $3P$, …). Then, in the second part of the algorithm, we calculate the points $amP$ with huge (i.e. “giant”) increments for $am$ ($1mP$, $2mP$, $3mP$, …, where $m$ is a huge number).
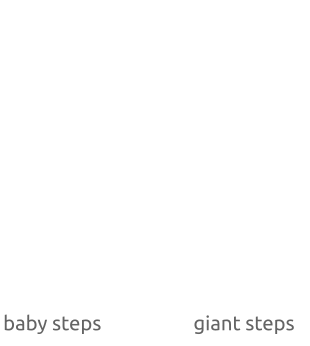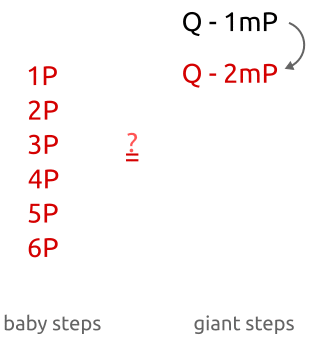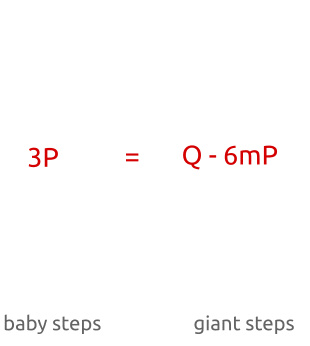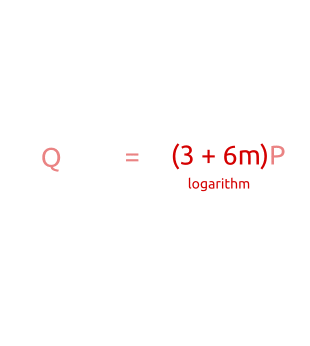
To understand why this algorithm works, forget for a moment that the points $bP$ are cached and take the equation $Q = amP + bP$. Consider what follows:
- When $a = 0$ we are checking whether $Q$ is equal to $bP$, where $b$ is one of the integers from 0 to $m$. This way, we are comparing $Q$ against all points from $0P$ to $mP$.
- When $a = 1$ we are checking whether $Q$ is equal to $mP + bP$. We are comparing $Q$ against all points from $mP$ to $2mP$.
- When $a = 2$ we are comparing $Q$ against all the points from $2mP$ to $3mP$.
- …
- When $a = m - 1$, we are comparing $Q$ against all points from $(m - 1)mP$ to $m^2 P = nP$.
In conclusion, we are checking all points from $0P$ to $nP$ (that is, all the possible points) performing at most $2m$ additions and multiplications (exactly $m$ for the baby steps, at most $m$ for the giant steps).
If you consider that a lookup on a hash table takes $O(1)$ time, it’s easy to see that this algorithm has both time and space complexity $O(\sqrt{n})$ (or $O(2^{k / 2})$ if you consider the bit length). It’s still exponential time, but much better than a brute-force attack.
Baby-step giant-step in practice
It may make sense to see what the complexity $O(\sqrt{n})$ means in practice. Let’s take a standardized curve: prime192v1 (aka secp192r1, ansiX9p192r1). This curve has order $n$ = 0xffffffff ffffffff ffffffff 99def836 146bc9b1 b4d22831. The square root of $n$ is approximately 7.922816251426434 · 1028 (almost eighty octillions).
Now imagine storing $\sqrt{n}$ points in a hash table. Suppose that each point requires exactly 32 bytes: our hash table would need approximately 2.5 · 1030 bytes of memory. Looking on the web, it seems that the total world storage capacity is in the order of the zettabyte (1021 bytes). This is almost ten orders of magnitude lower than the memory required by our hash table! Even if our points took 1 byte each, we would be still very far from being able to store all of them.
This is impressive, and is even more impressive if you consider that prime192v1 is one of the curves with the lowest order. The order of secp521r1 (another standard curve from NIST) is approximately 6.9 · 10156!
Playing with baby-step giant-step
I made a Python script that computes discrete logarithms using the baby-step giant-step algorithm. Obviously it only works with curves with small orders: don’t try it with secp521r1, unless you want to receive a MemoryError.
It should produce an output like this:
Curve: y^2 = (x^3 + 1x - 1) mod 10177
Curve order: 10331
p = (0x1, 0x1)
q = (0x1a28, 0x8fb)
325 * p = q
log(p, q) = 325
Took 105 steps
Pollard’s ρ
Pollard’s rho is another algorithm for computing discrete logarithms. It has the same asymptotic time complexity $O(\sqrt{n})$ of the baby-step giant-step algorithm, but its space complexity is just $O(1)$. If baby-step giant-step can’t solve discrete logarithms because of the huge memory requirements, will Pollard’s rho make it? Let’s see…
First of all, another reminder of the discrete logarithm problem: given $P$ and $Q$ find $x$ such that $Q = xP$. With Pollard’s rho, we will solve a sightly different problem: given $P$ and $Q$, find the integers $a$, $b$, $A$ and $B$ such that $aP + bQ = AP + BQ$.
Once the four integers are found, we can use the equation $Q = xP$ to find out $x$: $$\begin{align*} aP + bQ & = AP + BQ \\ aP + bxP & = AP + BxP \\ (a + bx) P & = (A + Bx) P \\ (a - A) P & = (B - b) xP \end{align*}$$
Now we can get rid of $P$. But before doing so, remember that our subgroup is cyclic with order $n$, therefore the coefficients used in point multiplication are modulo $n$: $$\begin{align*} a - A & \equiv (B - b) x \pmod{n} \\ x & = (a - A)(B - b)^{-1} \bmod{n} \end{align*}$$
The principle of operation of Pollard’s rho is simple: we generate a pseudo-random sequence of points $X_1$, $X_2$, … where each $X = a_i P + b_i Q$. The sequence can be generated using a pseudo-random function $f$ like this: $$(a_{i + 1}, b_{i + 1}) = f(X_i)$$
That is: the pseudo-random function $f$ takes the latest point $X_i$ in the sequence as the input, and gives the coefficients $a_{i + 1}$ and $b_{i + 1}$ as the output. From there, we can calculate $X_{i + 1} = a_{i + 1} P + b_{i + 1} Q$; we can then input $X_{i + 1}$ into $f$ again and repeat.
It doesn’t really matter how $f$ works internally (although certain functions may yield results faster than others), what matters is that $f$ determines the next point in the sequence based on the previous one, and that all the $a_i$ and $b_i$ coefficients are known by us.
By using such $f$, sooner or later we will see a loop in our sequence. That is, we will see a point $X_j = X_i$.

This picture resembles the Greek letter ρ (rho), hence the name.
The reason why we must see the cycle is simple: the number of points is finite, hence they must repeat sooner or later. Once we see where the cycle is, we can use the equations above to figure out the discrete logarithm.
The problem now is: how do we detect the cycle in an efficient way?
Tortoise and Hare
To detect cycles, we have an efficient method: the tortoise and hare algorithm (also known as Floyd’s cycle-finding algorithm). The picture below shows the principle of operation of the tortoise and hare method, which is at the core of Pollard’s rho.
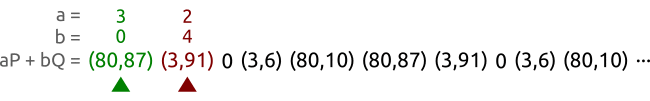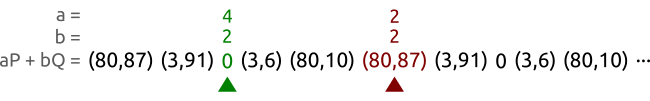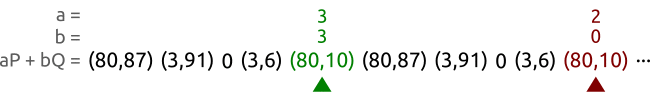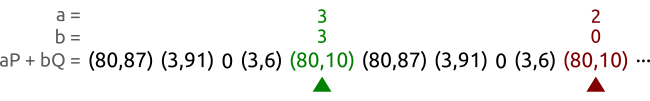
We walk a sequence of pairs at different speeds until we find two different pairs $(a, b)$ and $(A, B)$ that produce the same point. In this case, we have found the pairs $(3, 3)$ and $(2, 0)$ that allow us to calculate the logarithm as $x = (3 - 2)(0 - 3)^{-1} \bmod{5} = 3$. And in fact we correctly have $Q = 3P$.
We take two pets, the tortoise and the hare, and make them walk our sequence of points from left to right. The tortoise (the green spot in the picture) is slow and reads each point one by one; the hare (represented in red) is fast and skips a point at every step.
After some time both the tortoise and the hare will have found the same point, but with different coefficient pairs. Or, to express that with equations, the tortoise will have found a pair $(a, b)$ and the hare will have found a pair $(A, B)$ such that $aP + bQ = AP + BQ$.
It’s easy to see that this algorithm requires constant memory ($O(1)$ space complexity). Calculating the asymptotic time complexity is not that easy, but we can build a probabilistic proof that shows how the time complexity is $O(\sqrt{n})$, as we have already said. The proof is based on the “birthday paradox”, which is about the probability of two people having the same birthday, where here we are concerned about the probability of two $(a, b)$ pairs yielding the same point.
Playing with Pollard’s ρ
I’ve built a Python script that computes discrete logarithms using Pollard’s rho. It is not the implementation of the original Pollard’s rho, but a slight variation of it (I’ve used a more efficient method for generating the pseudo-random sequence of pairs). The script contains some useful comments, so read it if you are interested in the details of the algorithm.
This script, like the baby-step giant-step one, works on a tiny curve, and produces the same kind of output.
Pollard’s ρ in practice
We said that baby-step giant-step can’t be used in practice, because of the huge memory requirements. Pollard’s rho, on the other hand, requires very few memory. So, how practical is it?
Certicom launched a challenge in 1998 to compute discrete logarithms on elliptic curves with bit lengths ranging from 109 to 359. As of today, only 109-bit long curves have been successfully broken. The latest successful attempt was made in 2004. Quoting Wikipedia:
The prize was awarded on 8 April 2004 to a group of about 2600 people represented by Chris Monico. They also used a version of a parallelized Pollard rho method, taking 17 months of calendar time.
As we have already said, prime192v1 is one of the “smallest” elliptic curves. We also said that Pollard’s rho has $O(\sqrt{n})$ time complexity. If we used the same technique as Chris Monico (the same algorithm, on the same hardware, with the same number of machines), how much would it take to compute a logarithm on prime192v1?
$$17\ \text{months}\ \times \frac{\sqrt{2^{192}}}{\sqrt{2^{109}}} \approx 5 \cdot 10^{13}\ \text{months}$$
This number is pretty self-explanatory and gives a clear idea of how hard it can be to break a discrete logarithm using such techniques.
Pollard’s ρ vs Baby-step giant-step
I decided to put the baby-step giant-step script and the Pollard’s rho script together with a brute-force script into a fourth script to compare their performances.
This fourth script computes all the logarithms for all the points on the “tiny” curve using different algorithms and reports how much time it did take:
Curve order: 10331
Using bruteforce
Computing all logarithms: 100.00% done
Took 2m 31s (5193 steps on average)
Using babygiantstep
Computing all logarithms: 100.00% done
Took 0m 6s (152 steps on average)
Using pollardsrho
Computing all logarithms: 100.00% done
Took 0m 21s (138 steps on average)
As we could expect, the brute-force method is tremendously slow if compared to the others two. Baby-step giant-step is the faster, while Pollard’s rho is more than three times slower than baby-step giant-step (although it uses far less memory and fewer number of steps on average).
Also look at the number of steps: brute force used 5193 steps on average for computing each logarithm. 5193 is very near to 10331 / 2 (half the curve order). Baby-step giant-steps and Pollard’s rho used 152 steps and 138 steps respectively, two numbers very close to the square root of 10331 (101.64).
Final consideration
While discussing these algorithms, I have presented many numbers. It’s important to be cautious when reading them: algorithms can be greatly optimized in many ways. Hardware can improve. Specialized hardware can be built.
The fact that an approach today seems impractical, does not imply that the approach can’t be improved. It also does not imply that other, better approaches exist (remember, once again, that we have no proofs for the complexity of the discrete logarithm problem).
Shor’s algorithm
If today’s techniques are unsuitable, what about tomorrow’s techniques? Well, things are a bit more worrisome: there exist a quantum algorithm capable of computing discrete logarithms in polynomial time: Shor’s algorithm, which has time complexity $O((\log n)^3)$ and space complexity $O(\log n)$.
Quantum computers are still far from becoming sophisticated enough to run algorithms like Shor’s, still the need for quantum-resistant algorithms may be something worth investigating now. What we encrypt today might not be safe tomorrow.
ECC and RSA
Now let’s forget about quantum computing, which is still far from being a serious problem. The question I’ll answer now is: why bothering with elliptic curves if RSA works well?
A quick answer is given by NIST, which provides with a table that compares RSA and ECC key sizes required to achieve the same level of security.
| RSA key size (bits) | ECC key size (bits) |
|---|---|
| 1024 | 160 |
| 2048 | 224 |
| 3072 | 256 |
| 7680 | 384 |
| 15360 | 521 |
Note that there is no linear relationship between the RSA key sizes and the ECC key sizes (in other words: if we double the RSA key size, we don’t have to double the ECC key size). This table tells us not only that ECC uses less memory, but also that key generation and signing are considerably faster.
But why is it so? The answer is that the faster algorithms for computing discrete logarithms over elliptic curves are Pollard’s rho and baby-step giant-step, while in the case of RSA we have faster algorithms. One in particular is the general number field sieve: an algorithm for integer factorization that can be used to compute discrete logarithms. The general number field sieve is the fastest algorithm for integer factorization to date.
All of this applies to other cryptosystems based on modular arithmetic as well, including DSA, D-H and ElGamal.
Hidden threats of NSA
An now the hard part. So far we have discussed algorithms and mathematics. Now it’s time to discuss people, and things get more complicated.
If you remember, in the last post we said that certain classes of elliptic curves are weak, and to solve the problem of trusting curves from dubious sources we added a random seed to our domain parameters. And if we look at standard curves from NIST we can see that they are all verifiably random.
If we read the Wikipedia page for “nothing up my sleeve”, we can see that:
- The random numbers for MD5 come from the sine of integers.
- The random numbers for Blowfish come from the first digits of $\pi$.
- The random numbers for RC5 come from both $e$ and the golden ratio.
These numbers are random because their digits are uniformly distributed. And they are also unsuspicious, because they have a justification.
Now the question is: where do the random seeds for NIST curves come from? The answer is, sadly: we don’t know. Those seeds have no justification at all.
Is it possible that NIST has discovered a “sufficiently large” class of weak elliptic curves and has tried many possible seeds until they found a vulnerable curve? I can’t answer this question, but this is a legit and important question. We know that NIST has succeeded in standardizing at least a vulnerable random number generator (a generator which, oddly enough, is based on elliptic curves). Perhaps they also succeeded in standardizing a set of weak elliptic curves. How do we know? We can’t.
What’s important to understand is that “verifiably random” and “secure” are not synonyms. And it doesn’t matter how hard the logarithm problem is, or how long our keys are, if our algorithms are broken, there’s nothing we can do.
With respect to this, RSA wins, as it does not require special domain parameters that can be tampered. RSA (as well as other modular arithmetic systems) may be a good alternative if we can’t trust authorities and if we can’t construct our own domain parameters. And in case you are asking: yes, TLS may use NIST curves. If you check https://google.com, you’ll see that the connection is using ECDHE and ECDSA, with a certificate based on prime256v1 (aka secp256p1).
That’s all!
I hope you have enjoyed this series. My aim was to give you the basic knowledge, terminology and conventions to understand what elliptic curve cryptography today is. If I reached my aim, you should now be able to understand existing ECC-based cryptosystems and to expand your knowledge by reading “not so gentle” documentation. When writing this series, I could have skipped over many details and use a simpler terminology, but I felt that by doing so you would have not been able to understand what the web has to offer. I believe I have found a good compromise between simplicity and completeness.
Note though that by reading just this series, you are not able to implement secure ECC cryptosystems: security requires us to know many subtle but important details. Remember the requirements for Smart’s attack and Sony’s mistake — these are just two examples that should teach you how easy is to produce insecure algorithms and how easy it is to exploit them.
So, if you are interested in diving deeper into the world of ECC, where to go from here?
First off, so far we have seen Weierstrass curves over prime fields, but you must know that there exist other kinds of curve and fields, in particular:
- Koblitz curves over binary fields. Those are elliptic curves in the form $y^2 + xy = x^3 + ax^2 + 1$ (where $a$ is either 0 or 1) over finite fields containing $2^m$ elements (where $m$ is a prime). They allow particularly efficient point additions and scalar multiplications.
Examples of standardized Koblitz curves are
nistk163,nistk283andnistk571(three curves defined over a field of 163, 283 and 571 bits). - Binary curves. They are very similar to Koblitz curves and are in the form $x^2 + xy = x^3 + x^2 + b$ (where $b$ is an integer often generated from a random seed). As the name suggests, binary curves are restricted to binary fields too. Examples of standardized curves are
nistb163,nistb283andnistb571. It must be said that there are growing concerns that both Koblitz and Binary curves may not be as safe as prime curves. - Edwards curves, in the form $x^2 + y^2 = 1 + d x^2 y^2$ (where $d$ is either 0 or 1). These are particularly interesting not only because point addition and scalar multiplication are fast, but also because the formula for point addition is always the same, in any case ($P \ne Q$, $P = Q$, $P = -Q$, …). This feature leverages the possibility of side-channel attacks, where you measure the time used for scalar multiplication and try to guess the scalar coefficient based on the time it took to compute. Edwards curves are relatively new (they were presented in 2007) and no authority such as Certicom or NIST have yet standardized any of them.
- Curve25519 and Ed25519 are two particular elliptic curves designed for ECDH and a variant of ECDSA respectively. Like Edwards curves, these two curves are fast and help preventing side-channel attacks. And like Edwards curves, these two curves have not been standardized yet and we can’t find them in any popular software (except OpenSSH, that supports Ed25519 key pairs since 2014).
If you are interested in the implementation details of ECC, then I suggest you read the sources of OpenSSL and GnuTLS.
Finally, if you are interested in the mathematical details, rather than the security and efficiency of the algorithms, you must know that:
- Elliptic curves are algebraic varieties with genus one.
- Points at infinity are studied in projective geometry and can be represented using homogeneous coordinates (although most of the features of projective geometry are not needed for elliptic curve cryptography).
And don’t forget to study finite fields and field theory.
These are the keywords that you should look up if you’re interested in the topics.
Now the series is officially concluded. Thank you for all your friendly comments, tweets and mails. Many have asked me if I’m going to write other series on other closely related topics. The answer is: maybe. I accept suggestions, but I can’t promise anything.
Thanks for reading and see you next time!
Comments